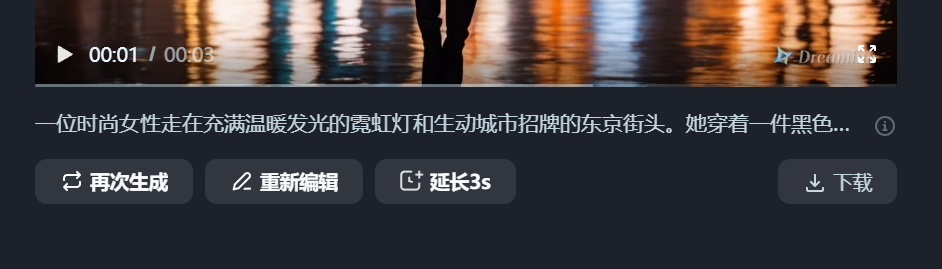
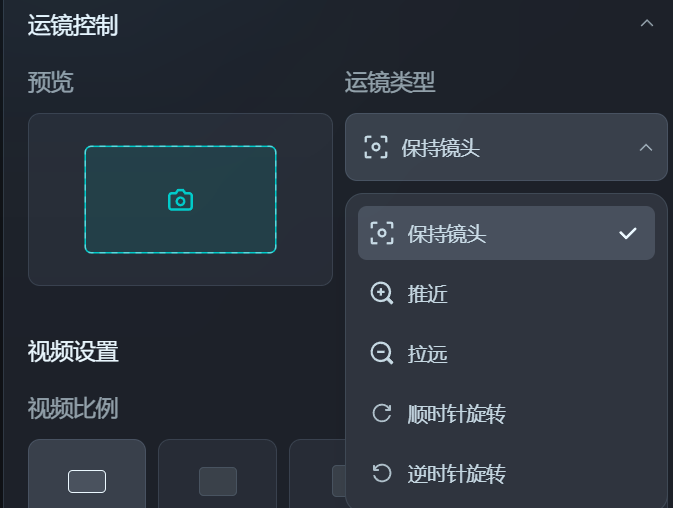
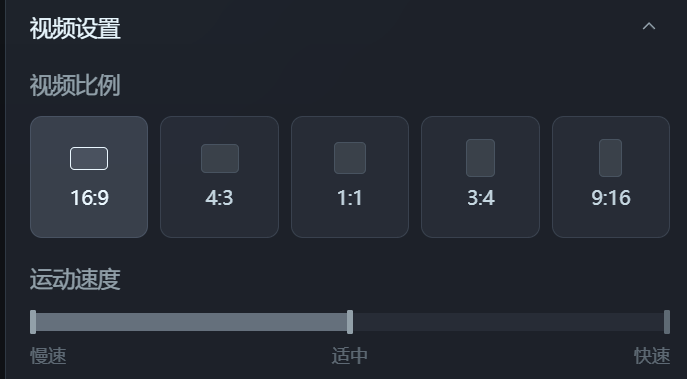
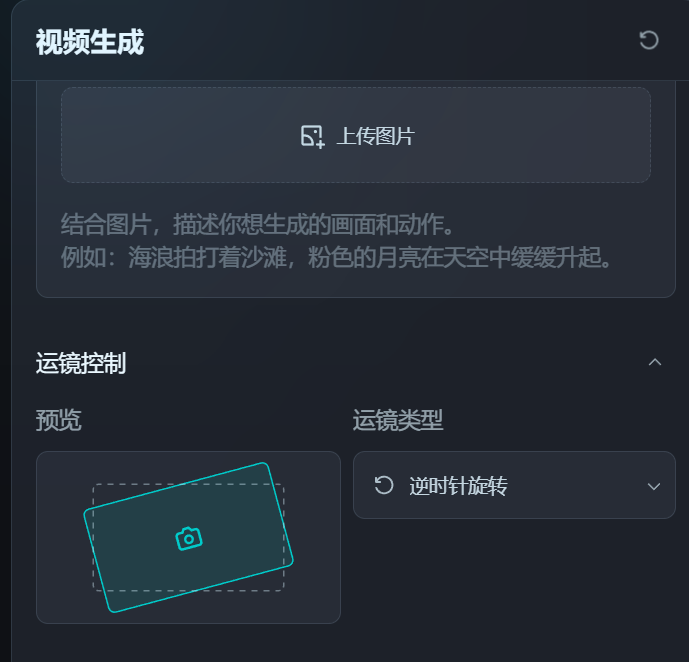
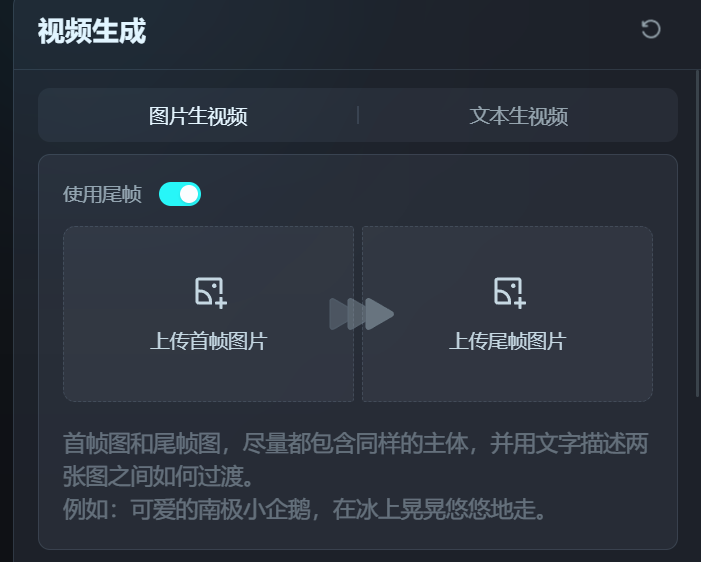
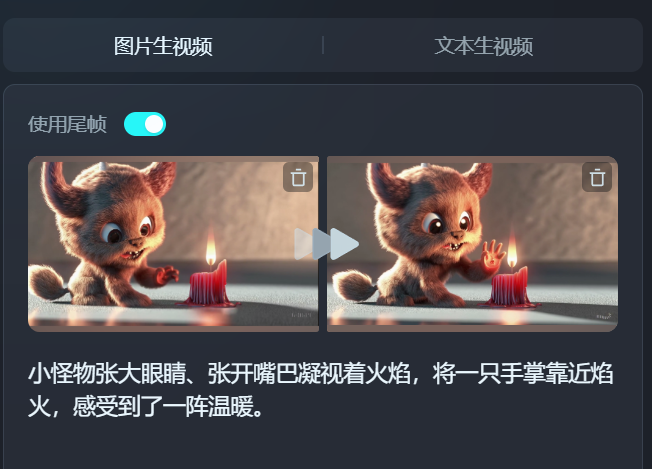
好低调!字节Dreamina全面开放内测了,效果够惊艳吗?Ta眼中的“Sora女士”原来是这样!纳豆(收徒)2024年04月11日 09:29:26更新关注12536 字节Dreamina的内测范围扩大了!一个月前小编填写过一次内测收集问卷,当时并未拿到初始100人(据说)的名额。 但在今天上午再次申请后,下午便惊喜地发现已经开通了Dreamina的文生视频功能! 再次申请只需选择两个问题,一是有无AI视频产品的使用经验,二是是否有在工作中大量使用AI视频生成的需求。完成后就可以等待上手测试啦!想体验的朋友们移步,点击“视频生成”选项即可:https://dreamina.jianying.com/ai-tool/home。 最最让我好奇的还是:Dreamina眼中的“Sora女士”会是什么样呢? 让我们先来瞅瞅用“Sora女士”的prompt生成的视频效果如何吧! 截图来源:Sora官方视频 prompt:一位时尚女性走在充满温暖发光的霓虹灯和生动城市招牌的东京街头。她穿着一件黑色皮夹克,一条长红裙,黑色靴子,并提着一个黑色手提包。她戴着太阳镜,涂着红唇膏。她自信而随意地走着。街道潮湿而反光,形成了五彩斑斓的灯光的镜面效果。许多行人来来往往。 太短了!这段视频在两分钟内完成了生成(PS:小编的网速一般)。可惜整个视频的时长只有3秒钟……要知道,Sora之所以这么惊艳,很大程度上来源于视频能坚持10s以上“不崩坏”。不过,也可以给Dreamina生成的视频再续3秒,但那就是另外的价格了(需要开通会员,功能按钮见下图)。 对于视频的第一印象就是——“Dreamina女士”真的好拽姐!如果说Sora理解的“自信而随意”是坚毅而知性的,Dreamina则有种Z时代的叛逆和张狂在身上。 先说说Dreamina的优点。Dreamina在提示词的这场命题作文里拿到了所有大的得分点,例如霓虹灯街头、皮夹克、墨镜、红裙红唇等关键词都抓得不错。 但是,Dreamina的硬伤也有,还不少: 手指:AI生图最难攻克的手指,在生视频时又又又难死AI了,拿着包的那只手,手指数目一直不稳定 腿部动作:两腿的交叉不自然,看起来一直在迈右腿 面部:通过神情呈现“随意”这一关键词时,嘴唇有点“乱飞” 地面:地面潮湿的效果“注水”过猛,水直接流动起来了 此外,和sora视频中清晰的出现了日文招牌不同,“Dreamina女士”街头的招牌非常模糊,看起来比较像中文。此外发生手提包理解成了单肩挎包这样的小瑕疵。 Dreamina女士生成全过程 Dreamina的界面友好、清晰,很容易上手。 用户每天可以获得免费的60积分,积分只能当天使用无法累积。每次生成视频需要12积分,也就是可以免费做5条AI视频(合计15s)。 Dreamina提供了文生视频和图片生视频两种模式,这里选择文生视频(图生视频测试见下一节)。 Dreamina允许用户对运镜类型进行控制。在OpenAI所提供的Sora女士视频里,大部分时间镜头都是与人物同步移动的,所以这里选择了保持镜头。 在视频设置中,Dreamina提供了视频比例及运动速度的调整。 在第二次实验中,我们调整比例到竖屏的9:16,并让“Dreamina女士”走快点。 这次视频效果竟然明显好了不少!虽然这次人物拎了两只手提包,但是地面、“Dreamina女士”的面部表情和腿部动作都得到了改善。推测这是因为,剪映下的Dreamina天生具有为抖音服务的属性,因此在竖屏视频上做了更多的训练。 为了继续测测Dreamina的想象力,使用了Sora的“咖啡杯与海盗船”考题。 prompt:两艘海盗船,在一杯咖啡中,航行时的逼真特写视频。 Dreamina 只生成了一搜海盗船,还有一个飘忽的人物在咖啡杯中,同时也没有很好地展现航行动作。看来生成超现实的场景对于Dreamina来说还是有点难。 首尾帧生视频,新意够了实现还差点 图生视频功能的测试中依然选择了Sora提供的苏尔加雷角海滩图片。 prompt:无人机视角下的大苏尔加雷角海滩,巨浪拍打着崎岖的悬崖。撞击的蓝色海水形成白色的浪尖,而落日的金色光芒照亮了岩石海岸。远处的小岛上有一座灯塔,绿色的灌木丛覆盖了悬崖的边缘。从道路陡峭下降到海滩是一种戏剧性的壮举,悬崖边缘突出在海面上。这是一种捕捉海岸原始美丽和太平洋海岸公路崎岖景观的视角。 图生视频功能仍然允许再输入提示词,不过为了考察AI是否能识别出“应该”运动的物体,这里选择不再输入提示。同时,这次体验了镜头顺时针旋转的效果。不过在预览中发现,目前Dreamina只支持平面的旋转效果(无法实现Sora这支视频向纵深旋转的效果)。 在无提示下,Dreamina也能很好地get到我们想要的海浪生成效果。美中不足的是,近处与远处的海水流动方向并不一致。 另外,我们还发现Dreamina有一个很独特的首尾帧功能!好家伙,以后的动画,岂不是开局一张图、结局一张图中间全部靠AI? 我们使用两张截图,尝试对Sora的“小怪物”视频进行复刻。 prompt: 看起来创新又好用的功能结果有点不尽如人意!最该动的手掌偏偏纹丝不动,明明首尾帧中的手掌位置和形态都变化了,且也有提示词强调。 这次生成的效果可以说离谱。小怪物张开嘴巴凝视火焰,被生成出嘴巴喷火的状态。同时,由于提示词不严谨地写成了“焰火”,所以Dreamina干脆就在蜡烛上飞了个烟花出来。这个事情告诉我们提示词必须要严谨,连断句也要仔细推敲,尽量写得非常直白易懂。 看来,视频生成模型真的不太懂物理世界,但是这又很贴合怪物世界……唉。 写在最后 在搜索Dreamina时,我们经常看到“复现Sora”“不输Sora”等评价。 但客观来说,这些评价多少有点“偏袒自家孩子”的意思了。即使从3秒视频的效果来看,我们也能看出Dreamina与Sora之间还存在着相当的差距。 即使有诸多不足,但在试用Dreamina的过程中我仍然觉得非常兴奋,既有接触新技术的新奇,也有对国内技术者的敬意。在视频生成技术落后OpenAI一两年,并且被算力“卡脖子”的背景下,字节仍然这么迅速地动作,并通过广泛的内测让我们看到了视频生成在短期内To C的可能。这是非常有勇气的、令人鼓舞的决定。 在Sora官方进驻Tik Tok时,AI视频生成工具会不会取代现在的短视频平台一度成为热议的话题。 而字节能依托现有的产品矩阵,“降大任”于剪映,让我们看到了一家中国互联网巨头的勃勃野心与强大的生命力——平台和工具,字节跳动都要。 © 版权声明如有侵权,请联系站长删除THE END杂谈 喜欢就支持一下吧点赞36 分享QQ空间微博QQ好友海报分享复制链接收藏