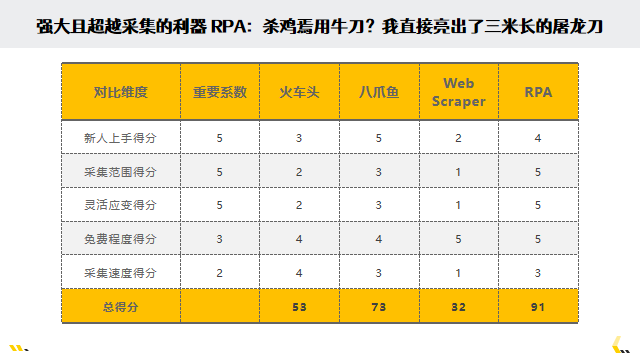
其实现在抓取数据是非常简单的,不需要再去专门去学个 python 有很多非编程的采集器,不需要专门学编程语言,基本上都是可视化配置,快速上手 这是我给非技术人员小白非常靠谱的建议 有人问我:数据采集用哪款工具比较好,火车头、八爪鱼、wbscraper 还是 RPA? 这个问题很难回答。能搞定问题就好。我呢,主要用 RPA。 我们有这么一张采集器的对比维度表 从新人上手,采集范围,灵活应变程度,采集速度这五个方面划分 重要系数是越重要的我会给分给的高一点 最后呢可以看看打分, 八爪鱼它的一个总分还比较高,火车头分数跟 WEB Scraper 会相对低很多, RPA 的分数是最高的,因为这几个方面 RPA 都可以很轻松的得分 还有人特别问到我:数据采集学习 RPA 还是 webscraper ? 我的答案是:这两者没有可比性。非要比较,那就是 RPA 比 webscraper 强 100 倍吧 问这个问题的老铁,对 RPA 基本上缺乏了解。可能是通过我的分享或者从别的地方知道 RPA 也可以做采集的工作,然后又恰巧知道 webscraper 的存在。毕竟 webscraper 是专为采集 数据采集,是一个很普遍的需求。在这个普遍的需求下,有大量的为采集而生的工具。webscraper 是这些众多采集中的一个,是以 Chrome 或者其他浏览器插件的形式存在 我使用过不下二十款采集工具,甚至还用 Excel 采集过网页,这种门槛极低但普适性极差 有过两三年主要使用火车头的经历。再后来就是两三年主要使用八爪鱼。这中间有尝试过其他的工具,比如集搜客、爬山虎、后羿采集。也有体验过各种浏览器采集插件,其中 webscraper 大概是最有名的。但在我的深度使用过的采集工具名单上,是没有 webscraper 的 为什么我没有重度使用过 webscraper 。主要是因为这工具学习难度大且局限性大,导致学习性价比差,市面上其他的工具很容易取代 webscraper 我说 webscraper 学习门槛高,很多人会觉得莫名其妙,容易上手不正是 webscraper 的特点吗?这玩意还能叫有学习门槛?这都属于采集中没有技术含量的鄙视链底端了。怎么到了我这里,就变成学习难度大了 webscraper 学习难度大不大,这要看跟谁比。跟写代码相比,那肯定简单的一匹 webscraper 可以实现无代码采集,但又有哪几款软件不是无代码采集呢?如果是跟八爪鱼、后羿采集器相比,那就是困难的一匹 对大多数人而言,能搞定 webscraper ,那么搞定八爪鱼就是一两个小时的事情。反过来,则是不太可能的。现阶段八爪鱼、后羿采集这类工具,具有很高的智能化特性,你输入链接,就能自动出数据或者提示你下一步的操作,你只需要做选择或者做确认就行了 说 webscraper 的局限性大,这也是成立的。就说 webscraper 能采集 90% 的网页内容,这搁在火车头、八爪鱼,只会采集的更多。至于很多提升采集效率和体验的功能,火车头、八爪鱼吊打 webscraper 我最早用火车头,就是图功能强大、易上手、在团队中好普及。早些年的火车头,就是采集器的代名词。那时候,火车头的破解版到处横飞 后来,八爪鱼采集器也出来了,就主要用了八爪鱼,倒不是因为八爪鱼功能更强大(个人认为火车头在大部分情况下比八爪鱼效率更高),而是学习门槛更低,更适合在团队普及 如果让我推荐一款最具普适性的采集器,我的推荐就是八爪鱼(没收广告费,我自己也几乎不用八爪鱼了)。知乎上、微信公众号上,很多人推荐 webscraper ,无外乎学习门槛低,功能强大,免费这三个特点。学习门槛低、功能强大是不成立的。免费确实是免费,八爪鱼、后羿采集的免费版也是能满足绝大多人的需求了。如果你想使用付费版,一些增值收费功能,也确实是 webscraper 无法提供的 再到后面,我更多的是用 RPA 来做采集的事情。不能说 RPA 采集优势全面压到了八爪鱼,而是 RPA 在某些方面更灵活 那 RPA 的学习难度如何?首先得搞清楚, RPA 不是专业的采集工具,采集只是其很小的一个功能模块。其上手难度高于八爪鱼,低于 webscraper 八爪鱼采集器有个明显的优势就是已经傻瓜式了。这会导致就算你真的啥也不会,输入一条连接,总是能给你整些数据的 而 RPA 呢,你鼠标点击所在就是数据所在,但需要你再加一个模块把数据保存下来(类似于你保存文件要选择保存到哪里,文件名是什么),不然机器人真不知道把数据放到哪里。所以 RPA 的门槛比八爪鱼还是要高些的,毕竟完全没有接触过 RPA 的人,不知道用鼠标选择数据,也不知道的如何把数据存放。所以, RPA 还是得要学学才能采集 那 RPA 的局限性如何?这正是 RPA 的采集优势体现,是其他采集工具很难追赶的地方 比如很常见的各种条件筛选采集,一般的采集器很难搞定或者压根搞不定 再比如很常见的多账号轮流采集。大部分网站对账号或者 IP 访问量是有频率限制的,或者每天有访问量限制。八爪鱼还能比较轻松应对这种情况,如果用 webscraper ,可能会非常难处理 虽然 webscraper 能采集大众点评这类网站,但将会采集的异常辛苦。还有,大众点评上要采集的数据已经图片化或者干脆就是加密了(也就是你肉眼看到的是数字,但审查出来的元素是一串乱码),不清楚八爪鱼、 webscraper 如何来解决这个问题? 再比如很多时候,采集的数据并不是通过一个个 URL 链接跳转得到,可能要操作多个步骤,经过多次跳转,才能看到最终的数据。那么八爪鱼、 webscraper 又能怎样搞定这些数据的采集?至于直接抓取 APP 数据,这个完全超出八爪鱼、 webscraper 的大纲了 还有各种判断条件采集,比如出现 A ,应该怎么做下一步;出现 B ,又应该怎么做下一步。等等等等 很多人推崇 webscraper ,一个很重要的原因就是 webscraper 是免费的,所以当然香。实际上对绝大多数人而言,主流的采集工具的免费版足以满足需求了 RPA 是不是免费的?不能一概而论。但 UiBot 是可以永久免费使用 如果你想学习采集,我的推荐是学习 RPA ,学习 UiBot 。RPA 有更广泛的应用场景,而且在数据采集方面,同样表现惊艳
数据采集,你大可不必去学编程

数据采集用哪款工具比较好

© 版权声明
如有侵权,请联系站长删除
THE END
喜欢就支持一下吧